Introduction¶
ECoPANN is designed to estimate parameters directly from the observational data sets, which is a fully ANN-based framework that is different from the Bayesian inference.
This part will briefly show you the basic principle of ECoPANN, however, we recommend that readers read our published paper for more details.
A brief introduction to ANN¶
An ANN, also called a neural network (NN), is a mathematical model that is inspired by the structure and functions of biological NNs, and it generally consists of an input layer, hidden layers, and an output layer (see Figure 1 below).
The ANN, composed of linear and nonlinear transformations of input variables, has been proven to be a “universal approximator”, which can represent a great variety of functions. This powerful property of the ANN allows its wide use in regression and estimation tasks.
The ANN aims to make a mapping from the input data to the output data; thus, for the task of parameter inference, the ANN actually learns a mapping between the measurement and the corresponding cosmological parameters.
Network architecture¶
There are two network structures used in ECoPANN: a) a single fully connected network with a few hidden layers, which is usually called multilayer perceptron (MLP, see Figure 1 below); b) a multibranch network (see Figure 2 below).
MLP can accept a set of data sets as inputs and output the corresponding cosmological (or theoretical) model parameters. Therefore, MLP is used to estimate parameters from one set of data sets.
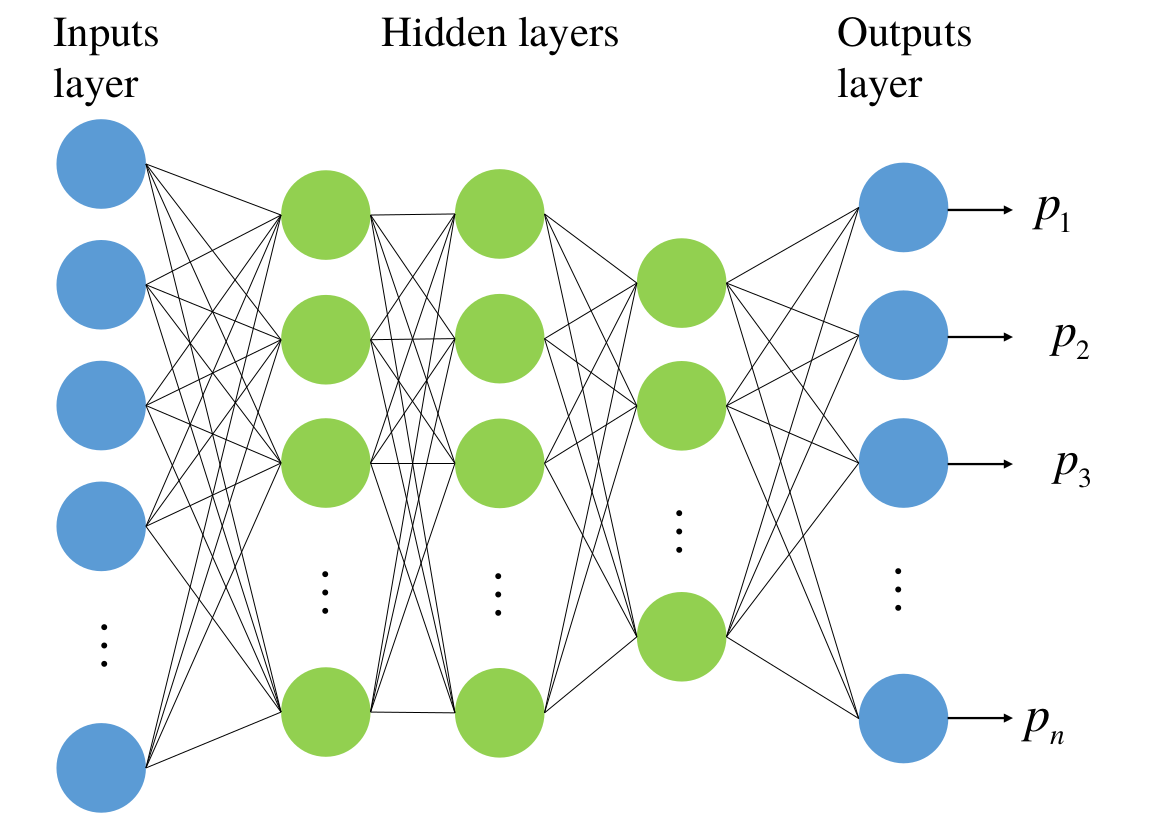
Figure 1. General structure of an MLP (Wang et al. (2020)).¶
For a multibranch network, each branch can accept a set of data sets as inputs and combine the information in the hidden layers and output the corresponding cosmological (or theoretical) model parameters. Therefore, multibranch network can accept multiple sets of data sets and thus can achieve a joint constraint on parameters using multiple sets of data sets.
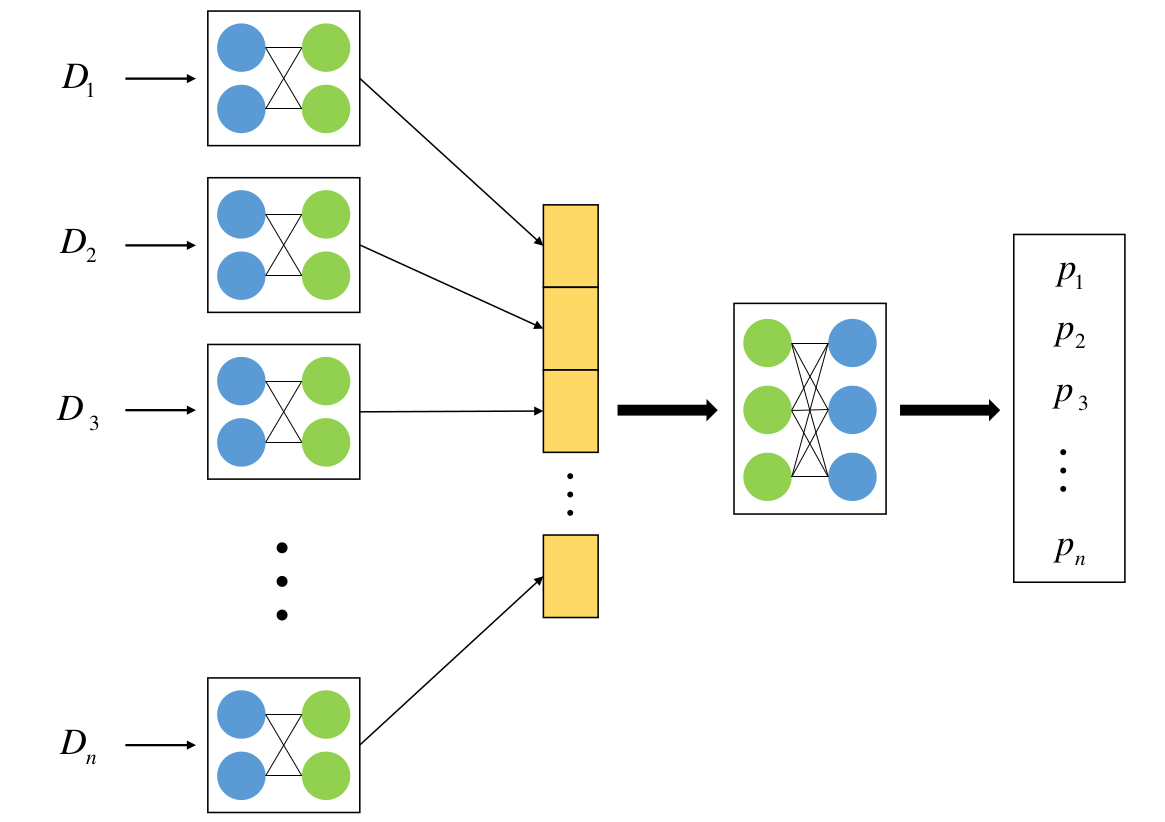
Figure 2. General structure of a multibranch network (Wang et al. (2020)).¶
Training process¶
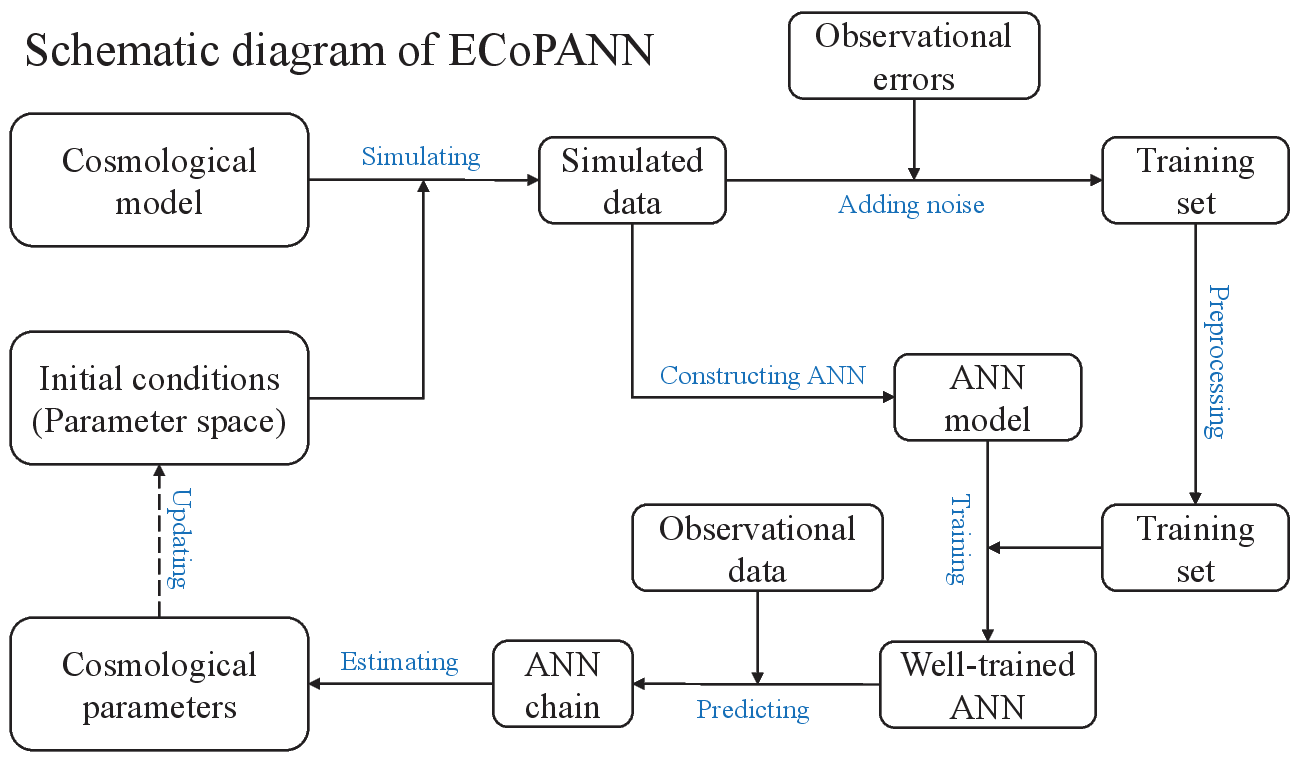
The training process (or the working principle) of ECoPANN is shown in the schematic diagram below. The key steps of the training process are as follows:
Set initial conditions for cosmological parameters, which are intervals of parameters.
Build a cosmological model instance and pass it to ECoPANN, and the training set will be simulated automatically by using the instance.
Pass the errors of the observational data to ECoPANN, and then random noise will be automatically added to the training set. Furthermore, the training set will be preprocessed.
After the training sets are preprocessed, an ANN model will be built automatically according to the size of the mock data.
Feed the training set to the ANN model, and the model will be well trained after thousands of epochs.
Simulate random samples using the observational data and feed them to the well-trained ANN model, and then a chain of parameters will be produced.
Posterior distribution of parameters can be further obtained by using the chain. Then, the parameter space to be learned will be updated according to the posterior distribution of parameters.
Parameter inference¶
After the seven steps illustrated above, we can obtain an ANN chain and the corresponding posterior distribution of parameters. However, the initial conditions of the parameters may not match the true parameters, so this posterior distribution may be a biased result.
To solve this problem, we need to do several realizations of the pipeline and update the parameter space after each realization. In the early part of the training process, the chain will not stable and we call this part burn-in. After several realizations, the posterior distribution of parameters will reach stable values, and the chains can be used for parameter inference.